Masked Autoencoder mit CIFAR-10
Bachelorarbeit: Self-Supervised Learning mit Vision Transformers - 90% Accuracy auf CIFAR-10
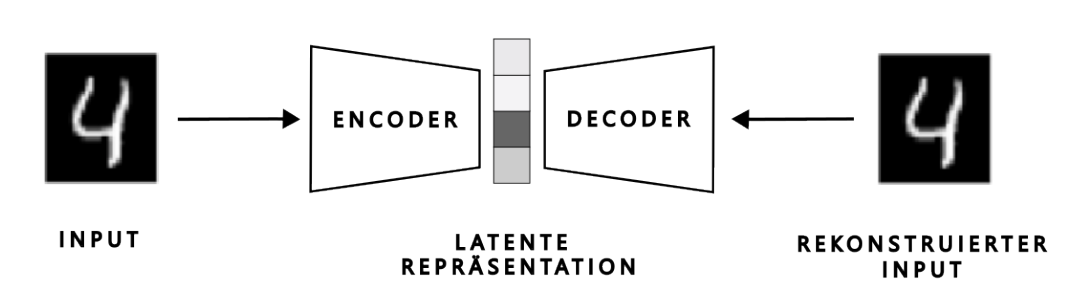
Überblick
In meiner Bachelorarbeit habe ich Masked Autoencoders (MAE) für den CIFAR-10 Datensatz implementiert und untersucht. Das Projekt demonstriert die Effektivität von Self-Supervised Learning auch für kleinere Bilddatensätze und erreicht nach Finetuning eine Genauigkeit von ca. 90% auf CIFAR-10.
Motivation
Masked Autoencoders haben sich bei großen Datensätzen wie ImageNet als äußerst erfolgreich erwiesen. Meine Arbeit untersucht, ob dieser Ansatz auch für kleinere Datensätze wie CIFAR-10 (32×32 Pixel) effektiv ist und welche Anpassungen notwendig sind.
Architektur
Das Projekt basiert auf einer Vision Transformer (ViT) Architektur mit Encoder-Decoder Struktur.
Encoder
- Verarbeitet nur die sichtbaren (nicht-maskierten) Patches
- Reduziert Rechenaufwand durch kleinere Input-Dimension
- Lernt kompakte Repräsentationen der sichtbaren Bildbereiche
Decoder
- Rekonstruiert die maskierten Patches aus den Encoder-Embeddings
- Leichtgewichtige Architektur (geringere Tiefe als Encoder)
- Nutzt Position Embeddings für räumliche Information
Two-Phase Training
Phase 1: Pretraining (Self-Supervised)
- Maskierungsstrategie: Random Masking mit konfigurierbarer Ratio
- Augmentationen: Flexible Pipeline für verschiedene Transformationen
- Loss Functions: Verschiedene Rekonstruktions-Losses getestet
- U-MAE Variante: Experimentelle Erweiterung implementiert
- Tracking: Weights & Biases für Metriken und Hyperparameter
Phase 2: Finetuning (Supervised)
- Pretrained Encoder wird für Klassifikation adaptiert
- Classifier Head (10 Klassen für CIFAR-10)
- Vergleich mit Vanilla ViT Tiny Baseline
- Evaluation des Pretraining-Effekts
Technische Anpassungen für CIFAR-10
CIFAR-10 unterscheidet sich deutlich von ImageNet (32×32 vs. 224×224 Pixel). Folgende Anpassungen waren notwendig:
- Kleinere Patch-Größe: Angepasst an 32×32 Bildgröße
- Reduzierte Embedding-Dimensionen: Proportional zur Bildgröße
- Optimierte Decoder-Tiefe: Balance zwischen Kapazität und Überanpassung
- Angepasste Maskierungsraten: Optimiert für kleinere Auflösung
Experimente & Vergleiche
Das Projekt ermöglicht einen direkten Vergleich zwischen drei Ansätzen:
MAE Encoder + Classifier (mit Pretraining)
Self-Supervised Pretraining gefolgt von Supervised Finetuning. Profitiert von gelernten Repräsentationen.
MAE Encoder + Classifier (ohne Pretraining)
Direktes Training von Grund auf. Baseline zur Evaluation des Pretraining-Effekts.
Vanilla ViT Tiny
Standard Vision Transformer von Grund auf trainiert. Architektur-unabhängiger Vergleich.
Ergebnisse
- Accuracy: ~90% auf CIFAR-10 Test-Set
- Pretraining-Vorteil: Deutlich schnellere Konvergenz im Finetuning
- Generalisierung: Robustere Repräsentationen durch Self-Supervised Learning
- Effizienz: Weniger Labels für vergleichbare Performance nötig
Implementation Details
- Framework: Jupyter Notebooks (MAE_Pretrain.ipynb, MAE_Finetune.ipynb)
- Plattform: Google Colab / Kaggle (GPU-beschleunigt)
- Experiment Tracking: Weights & Biases Integration
- Checkpointing: Best Model Saving basierend auf Validation Accuracy
- Reproduzierbarkeit: Alle Hyperparameter konfigurierbar
Erkenntnisse
Die Arbeit zeigt, dass Masked Autoencoders auch für kleinere Datensätze wie CIFAR-10 effektiv sind, wenn die Architektur entsprechend angepasst wird. Self-Supervised Learning kann die benötigte Menge an gelabelten Daten reduzieren und führt zu robusteren Feature-Repräsentationen.
Weitere Bilder

